|
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
术语“大数据”是大型数据集,其中包括体积庞大,高速,以及各种由与日俱增的数据的集合。使用传统的数据管理系统,它是难以加工大型数据。因此,Apache软件基金会推出了一款名为Hadoop的解决大数据管理和处理难题的框架。
Hadoop
Hadoop是一个开源框架来存储和处理大型数据在分布式环境中。它包含两个模块,一个是MapReduce,另外一个是Hadoop分布式文件系统(HDFS)。
MapReduce:它是一种并行编程模型在大型集群普通硬件可用于处理大型结构化,半结构化和非结构化数据。
HDFS:Hadoop分布式文件系统是Hadoop的框架的一部分,用于存储和处理数据集。它提供了一个容错文件系统在普通硬件上运行。
Hadoop生态系统包含了用于协助Hadoop的不同的子项目(工具)模块,如Sqoop, Pig 和 Hive。
Sqoop: 它是用来在HDFS和RDBMS之间来回导入和导出数据。
Pig: 它是用于开发MapReduce操作的脚本程序语言的平台。
Hive: 它是用来开发SQL类型脚本用于做MapReduce操作的平台。
注:有多种方法来执行MapReduce作业:
传统的方法是使用Java MapReduce程序结构化,半结构化和非结构化数据。
针对MapReduce的脚本的方式,使用Pig来处理结构化和半结构化数据。
Hive查询语言(HiveQL或HQL)采用Hive为MapReduce的处理结构化数据。
Hive是什么?
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在 Amazon Elastic MapReduce。
Hive 不是
一个关系数据库
一个设计用于联机事务处理(OLTP)
实时查询和行级更新的语言
Hiver特点
它存储架构在一个数据库中并处理数据到HDFS。
它是专为OLAP设计。
它提供SQL类型语言查询叫HiveQL或HQL。
它是熟知,快速,可扩展和可扩展的。
Hive架构
下面的组件图描绘了Hive的结构:
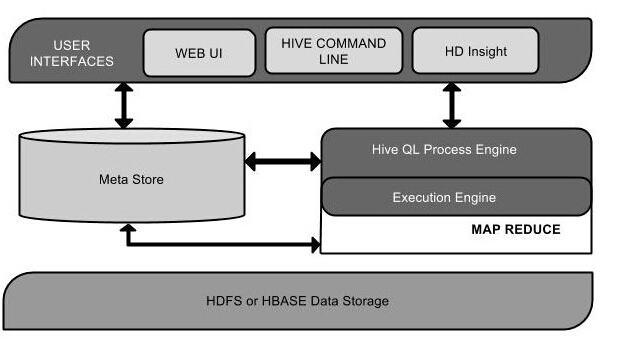
该组件图包含不同的单元。下表描述每个单元:

Hive工作原理
下图描述了Hive 和Hadoop之间的工作流程。
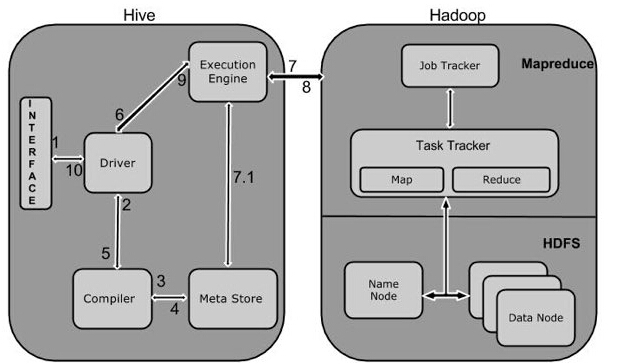
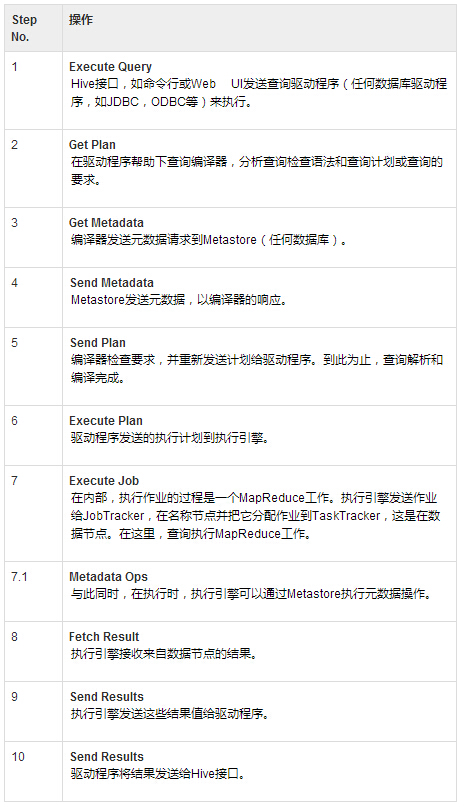
下表定义Hive和Hadoop框架的交互方式:
|


