|
在我们了解Flume和Sqoop之前,让我们研究数据加载到Hadoop的问题:
使用Hadoop分析处理数据,需要装载大量从不同来源的数据到Hadoop集群。
从不同来源大容量的数据加载到Hadoop,然后这个过程处理它,这具有一定的挑战。
维护和确保数据的一致性,并确保资源的有效利用,选择正确的方法进行数据加载前有一些因素是要考虑的。
主要问题:
1. 使用脚本加载数据
传统的使用脚本加载数据的方法,不适合于大容量数据加载到 Hadoop;这种方法效率低且非常耗时。
2. 通过 Map-Reduce 应用程序直接访问外部数据
提供了直接访问驻留在外部系统中的数据(不加载到Hadopp)到map reduce,这些应用程序复杂性。所以,这种方法是不可行的。
3.除了具有庞大的数据的工作能力,Hadoop可以在几种不同形式的数据上工作。这样,装载此类异构数据到Hadoop,不同的工具已经被开发。Sqoop和Flume 就是这样的数据加载工具。
SQOOP介绍
Apache Sqoop(SQL到Hadoop)被设计为支持批量从结构化数据存储导入数据到HDFS,如关系数据库,企业级数据仓库和NoSQL系统。Sqoop是基于一个连接器体系结构,它支持插件来提供连接到新的外部系统。
一个Sqoop 使用的例子是,一个企业运行在夜间使用 Sqoop 导入当天的生产负荷交易的RDBMS 数据到 Hive 数据仓库作进一步分析。
Sqoop 连接器
现有数据库管理系统的设计充分考虑了SQL标准。但是,每个不同的 DBMS 方言化到某种程度。因此,这种差异带来的挑战,当涉及到整个系统的数据传输。Sqoop连接器就是用来解决这些挑战的组件。
Sqoop和外部存储系统之间的数据传输在 Sqoop 连接器的帮助下使得有可能。
Sqoop 连接器与各种流行的关系型数据库,包括:MySQL, PostgreSQL, Oracle, SQL Server 和 DB2 工作。每个这些连接器知道如何与它的相关联的数据库管理系统进行交互。 还有用于连接到支持Java JDBC协议的任何数据库的通用JDBC连接器。 此外,Sqoop提供优化MySQL和PostgreSQL连接器使用数据库特定的API,以有效地执行批量传输。

除了这一点,Sqoop具有各种第三方连接器用于数据存储,
从企业数据仓库(包括Netezza公司,Teradata和甲骨文)到 NoSQL存储(如Couchbase)。但是,这些连接器没有配备Sqoop束; 这些需要单独下载并很容易地安装添加到现有的Sqoop。
FLUME 介绍
Apache Flume 用于移动大规模批量流数据到 HDFS 系统。从Web服务器收集当前日志文件数据到HDFS聚集用于分析,一个常见的用例是Flume。
Flume 支持多种来源,如:
“tail”(从本地文件,该文件的管道数据和通过Flume写入 HDFS,类似于Unix命令“tail”)
系统日志
Apache log4j (允许Java应用程序通过Flume事件写入到HDFS文件)。
在 Flume 的数据流
Flume代理是JVM进程,里面有3个组成部分 - Flume Source, Flume Channel 和 Flume Sink -通过该事件传播发起在外部源之后。
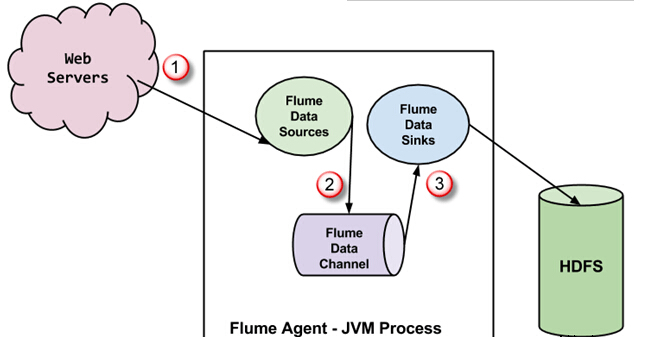
在上面的图中,由外部源(Web服务器)生成的事件是由Flume数据源消耗。 外部源将事件以目标源识别的格式发送给 Flume 源。
Flume 源接收到一个事件,并将其存储到一个或多个信道。信道充当存储事件,直到它由 flume消耗。此信道可能使用本地文件系统以便存储这些事件。
Flume 将删除信道,并存储事件到如HDFS外部存储库。可能会有多个 flume 代理,在这种情况下,flume将事件转发到下一个flume代理。
FLUME 一些重要特性
Flume 基于流媒体数据流灵活的设计。这是容错和强大的多故障切换和恢复机制。 Flume 有不同程度的可靠性,提供包括“尽力传输'和'端至端输送'。尽力而为的传输不会容忍任何 Flume 节点故障,而“终端到终端的传递”模式,保证传递在多个节点出现故障的情况。
Flume 承载源和接收之间的数据。这种数据收集可以被预定或是事件驱动。Flume有它自己的查询处理引擎,这使得在转化每批新数据移动之前它能够到预定接收器。
可能 Flume 包括HDFS和HBase。Flume 也可以用来输送事件数据,包括但不限于网络的业务数据,也可以是通过社交媒体网站和电子邮件消息所产生的数据。
自2012年7月Flume 发布了新版本 Flume NG(新一代),因为它和原来的版本有明显的不同,因为被称为 Flume OG (原代)。
|


